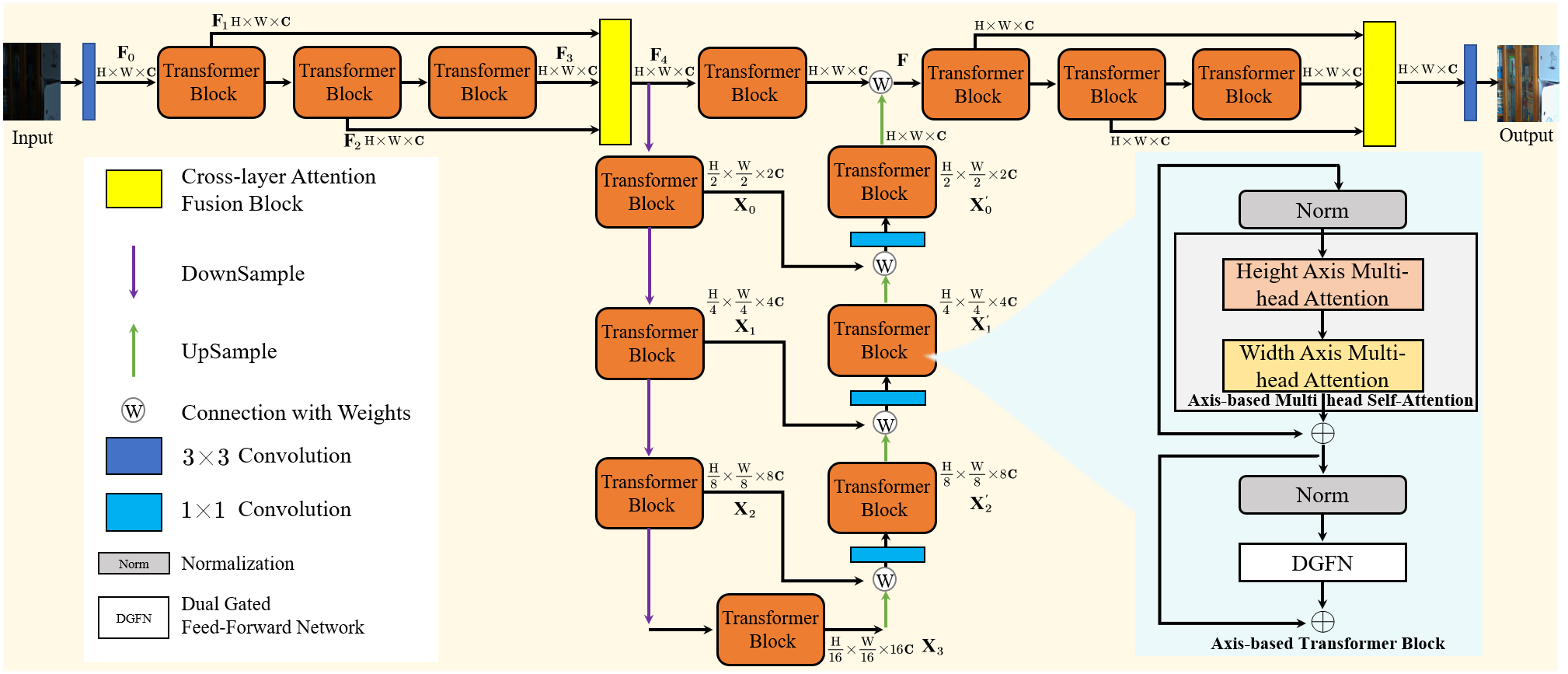
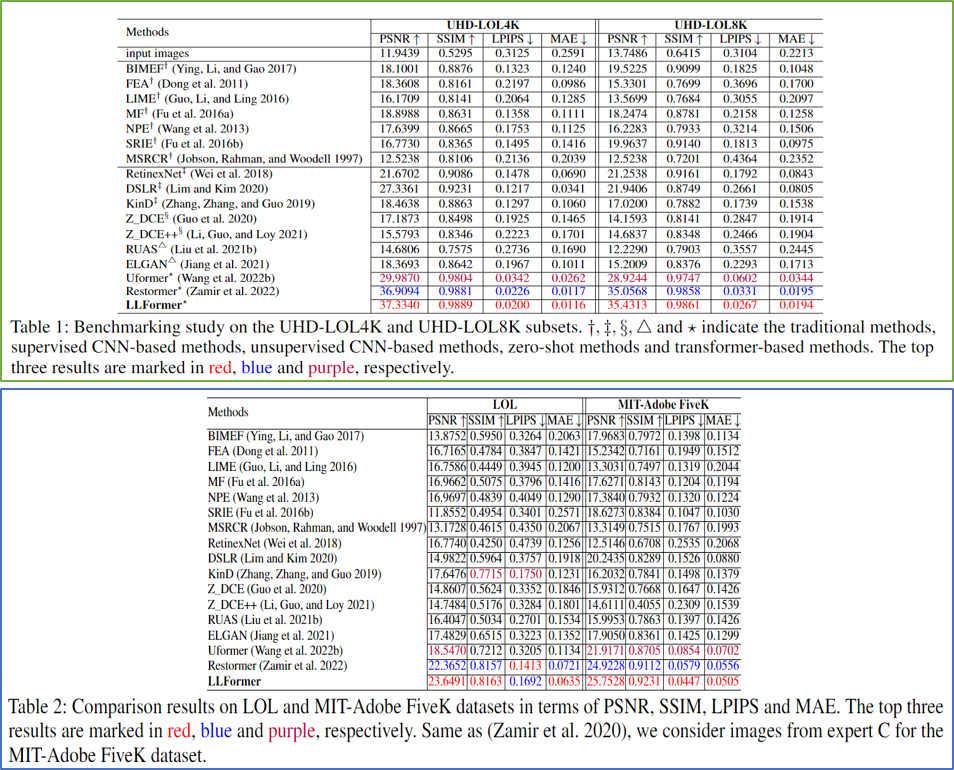
4K sample paired images (normal-light/low-light) from our UHD-LOL4K dataset. The images are from indoor and outdoor scenes, including buildings, streets, people, natural landsca etc.

8K sample paired images (normal-light/low-light) from our UHD-LOL8K dataset. The images are from indoor and outdoor scenes, including buildings, streets, people, natural landsca etc.